When people call their customer service, it means that they have an issue they want to solve. In this context, they don't want to listen to Beethoven (even if it is great music!) for 20 minutes while waiting to speak to an agent.
That's why calldesk works with the biggest French companies, for whom we create AI-powered voice agents. These voice agents are able to have conversations just like humans do and can manage millions of phone calls for our customers in order to help them build the future of the contact center.
Global overview
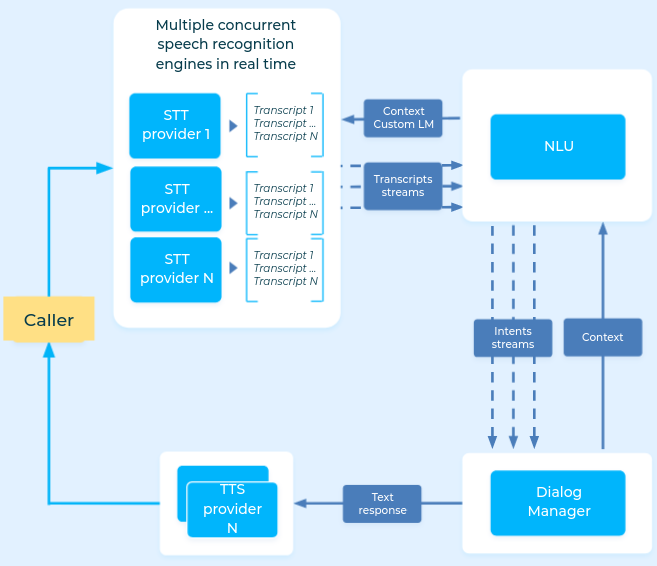
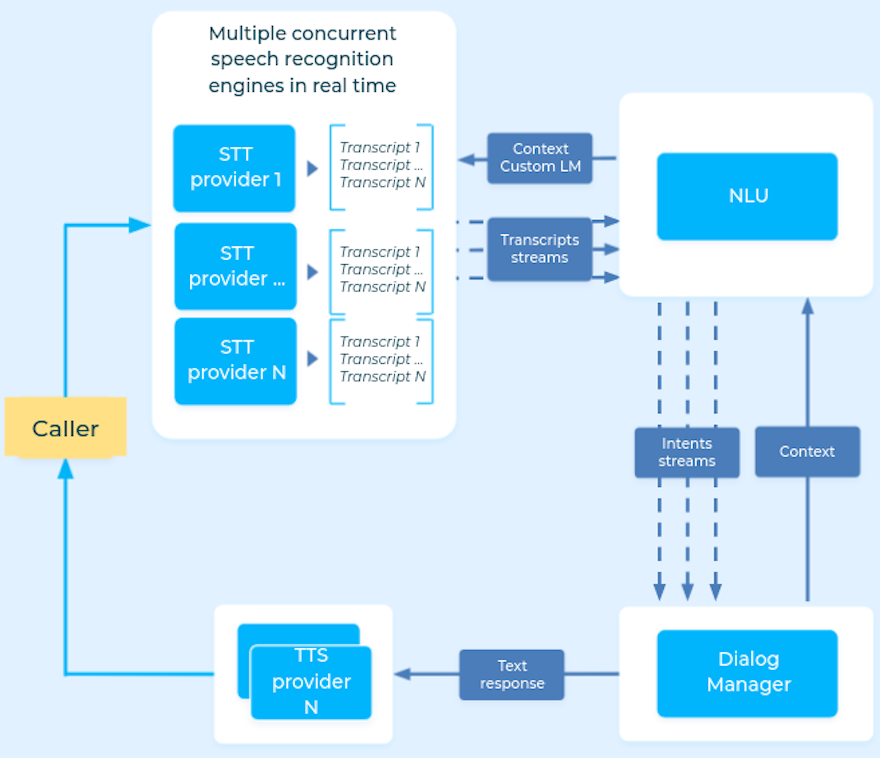
The diagram above shows, in a very simplified way, how our infrastructure works:
- The speech-to-text (STT) providers take the audio as an input and return a textual transcript
- The NLU module classifies the transcript to understand the caller intention and detect entities (last name, first name, address, contract number...)
- The dialog manager module decides where to go in the discussion graph depending on the matched intent and context
- The text-to-speech (TTS) component creates audio of the voice agent answer to be played to the caller
Our main challenges are to deliver a great experience to any caller that speaks to a voice agent, which means that:
- callers should not wait more than a few seconds to speak to a voice gent
- the voice agent must have a very low latency
- the understanding rate must be very good to reduce friction
- the voice agent must avoid any false positive intent classification
- caller's data should be shared with the voice agent
- the voice agent must be able to speak multiple languages
We're going to show you how the engineering team has overcome these challenges and which kind of infrastructure can respond to these needs.
Optimizing the waiting time
People are generally used to wait minutes before being able to speak to an agent, and this is one of the main pain points expressed while calling customer service. Using cloud technologies, calldesk was able to limit this waiting to only 2 seconds.
This is due to 2 main factors:
- 70% of contact centers are built with on-site servers, which are really hard to scale and very expensive
- Human agents have a limited amount of time during the day and can not handle the volume of phone calls
That's why we have built a very innovative serverless architecture using AWS Fargate to avoid having to maintain big servers and manage load efficiently. Each phone call is encapsulated in an AWS Fargate container with autoscaling rules. With this infrastructure, we can manage 600 new concurrent phone calls in less than 10 minutes, which is like having 600 new human agents in less than 10 minutes in a call center. Thanks to this scale capacity, our platform was able to handle the volume of phone calls the day after the lockdown, which was 5 times bigger, and by keeping a waiting time of fewer than 2 seconds.
This container service is also a pledge of security and reliability because the data won't be shared between containers and if a container fails or crashes, it won't have any impact on other containers.
This is why we are committed to a 99.99% SLA with our customers.
Having a very low latency
We can not offer a great experience to callers if the voice agents take seconds to respond, that's why we do not tolerate a response time of more than 1 second. We have chosen to use a streaming architecture between our STT providers, the NLU component, and the dialog manager.
Traditional dialog systems use a sequential system where the voice agent waits that the caller stops speaking to take the turn. It introduces a very high latency since the processing starts with a significant delay.
The streaming architecture that calldesk uses will send transcripts at every syllable that the caller pronounces for further processing and analysis. It means that the system can understand what the caller is saying even before he stops speaking, just like humans do. As an illustration, if I say "mon nom de famille", there is a big chance to expect the caller's last name even if I still haven't said it. This is exactly what happens with calldesk architecture: by analyzing the transcripts at every syllable, the voice agent is able to understand the user intent before the end of the sentence, which provides very low latency.
Offering a great understanding rate
Another must-have is to guarantee a very good understanding rate so that the callers can have a smooth conversation with the voice agents. One of the main innovations in the calldesk's product is to have multiple STT processing the audio in parallel in real-time.
We've built this system because depending on a provider, the understanding rate will be different. For instance, provider A might be very good at understanding french last name, but provider B might be better at understanding the general french language, while provider C might be excellent at understanding English. So, using only one STT provider would not guarantee the best performance and it totally makes sense to use multiple STT providers.
The voice agent is also automatically trained to understand which provider is the best for each question that they ask during a conversation. It allows our system to avoid using all providers if one of them gives the best transcript 95% of the time and that way it reduces transcriptions cost significantly.
Avoiding false-positive classification
A terrible experience for a caller would be to be misunderstood and going in the wrong branch of the conversation where he could not go back. We consider that a false positive is way more embarrassing than a false negative, which means that the voice agent prefers to say that he didn't understand if he is not sure rather than assuming an answer. That's why we have a default confidence threshold of 80% on the intent classification, which optimizes the balance between false positive and false negative. This threshold can be customized in our studio depending on the use case that the voice agent is handling.
Accessing caller's data
Another way to provide a great experience is to customize what the voice agent says depending on who is calling. Our voice agent can be integrated with any API in order to retrieve data about them and the problem they are facing while calling customer service.
For instance, if a person is calling his insurance to report damages, it can be great to retrieve his name using his phone number to welcome him. We can also retrieve information about his contract in order to be able to answer his question and be sure that the insurance covers the damages. It avoids unnecessary questions that would create friction.
Those integrations are developed by the engineering team and our Customer Success Manager can then reference it using the studio in order to use it easily.
Speaking multiple languages
One of the final challenges was to build voice agents with the ability to speak multiple languages, and that is something that we have kept in mind from day one. Our STT & TTS providers, NLU algorithms, and dialog manager component are able to speak more than 30 languages.
A voice agent is basically built for a specific use case and market chosen in collaboration with our clients. The voice agent language is chosen at the creation phase, but we have also built tools to be able to duplicate a voice agent in another language if our clients want to use it on another market.
STT components have also been trained with a large dataset including different accents, which enables voice agents to understand the same language but with variation in tone, vocabulary, and expressions.